Twitter’s API platform
Twitter is built on the robust conversations happening around the world via Tweets. With Twitter’s API platform, you’ll find endpoints to capitalize on the functionality and data contained within Tweets, and to build great experiences and solutions for your customers. These endpoints enable you to manage your Tweets, publish and curate Tweets, filter and search for Tweet topics or trends, and much more (Twitter, 2020).
The first step, in order to collect tweets, is to acquire an API key for Twitter’s Rest API. This is done by applying for one at Twitter’s developer portal1, luckily for me this process was very brief, and I got my API key within a day.
Twitter Developer Portal - Setting up an application
Having access to Twitter Developers Portal and API, enabled me to set up an application, which could then be used, to connect my R environment with Twitter’s API. This would allow me to manipulate the API using R, i.e., searching for Tweet topics or trends at specified time frames.
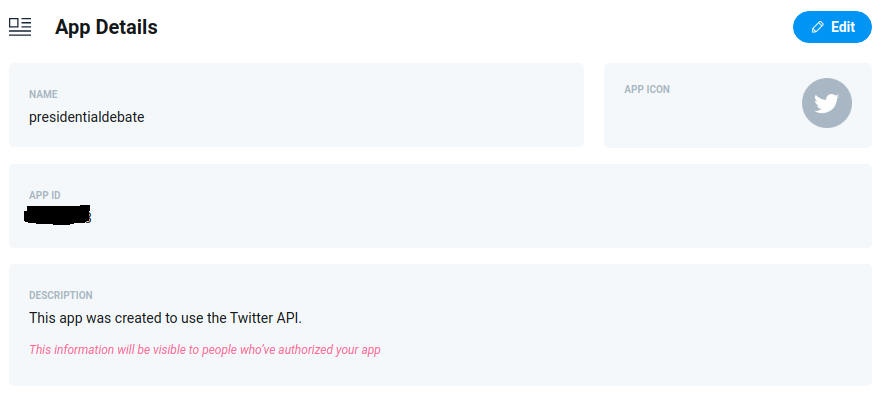
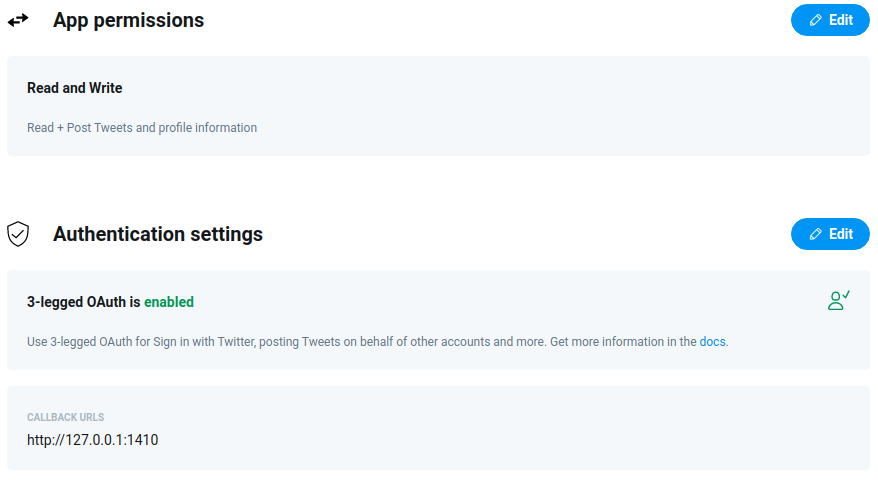 Figure 1.1 Configuring application on Twitter Developer Portal
Figure 1.1 Configuring application on Twitter Developer Portal
Note: It’s important, when configuring an application, to set a callback URL to 127.0.0.1:1410. This allows rtweet package to authenticate with your Twitter account.
Connecting R to the Twitter API
To connect R to the newly created application, an acccess token has to be created, using the application’s API key and secret. I used the create_token() function from rtweet package (Kearney, 2019) to do this, configuring it as follows:
library(rtweet)
key <- 'XXXXXXXXXXXXXXXXX' #this is not a key
secret <- 'XXXXXXXXXXXXXXXXXX'
# Connecting to Twitter API
twitter_token <- create_token(
app = "presidentialdebate",
consumer_key = key,
consumer_secret = secret
)Using create_token() from the rtweet package, saves this token as a variable in .Renviron, allowing one to use Twitter’s API without configuring a new token every session.
Collecting Tweets
Having set up an access token, Twitter’s API can now be manipulated through R, using the rtweet package (Kearney, 2019). To collect Tweets already sent, Tweets can be searched using the search_tweets() function, with the main parameters being q (search query) and n (number of desired tweets). As I wanted to perform multiple queries/searches with different search queries, number of tweets and time frames, around both the first and final presidential debate, I decided to create a .csv file (twitter_data.csv), where each row contains the specifications of a query/search.
Columns in twitter_data.csv
- since (date from which collection should begin)
- until (date at which collection should cease)
- n (number of tweets to collect)
- type (Search type recent/mixed/popular)
- term (Search term)
- path (path to save data)
- altpath (path to save data when cleaned)
By doing this, I won’t have to hard program all these different search specifications, into separate function calls, but can instead programatically pass each row to a search_tweets() call. This could be done by looping through the rows of twitter_data.csv, passing the specified parameters to search_tweets(), and saving the resulting data.frame as a RData (.rds) file at each iteration. For this purpose I wrapped search_tweets() along with saveRDS() to save the queries as .rds files, in a new function I named twitter_grab():
twitter_grab <- function(term, n, since, until, type, file) {
tweets <- search_tweets(q = term,
n = n,
include_rts = FALSE,
lang = "en",
since = since,
until = until,
type = type,
retryonratelimit = TRUE
)
saveRDS(tweets, file = file)
cat(file, "saved")
}As the Twitter API is limited, to only return tweets sent during the past 7 days, I had to collect the data on multiple occasions. First collecting tweets immediately after the first debate, then 7 days after and doing the same for the final debate. There are probably more elegant ways of doing this e.g., Cron jobs, but I decided to call the loop manually on multiple occasions, specifying, when calling the loop, which rows to query at each occasion.
# Grabbing tweets programmatically using a .csv file
ref <- read.csv('twitter_data.csv', stringsAsFactors = FALSE) #.csv file containing paths and search specs
# Looping throug data.frame ref calling twitter_grab() function
for (row in 31:nrow(ref)) {
twitter_grab(
ref$term[row],
ref$n[row],
ref$since[row],
ref$until[row],
ref$type[row],
ref$path[row]
)
}The above loop being the last I used collect Tweets sent during the week following the final Presidential debate. This loop iterates over the following subset of twitter_data.csv, and pass the search specifications to my function twitter_grab().
In total the Twitter data collection resulted in 42 queries (one for each row in twitter_data.csv), which was then saved as 42 individual RData (.rds) files.
Cleaning text variable in Twitter Data
Now that I have collected the Tweets, in order to use this data in a Natural Language Processing project, the text variable needs to be cleaned, i.e., removing links, mentions, hashtags and other special characters. To do this, I found some different examples on StackOverflow, using reprex to clean Tweets and modified this into a function:
library(tidyverse)
library(data.table)
# Cleaning function modified from StackOverflow
clean_tweets <- function(x) {
x %>%
str_remove_all(" ?(f|ht)(tp)(s?)(://)(.*)[.|/](.*)") %>% #removes links
str_replace_all("&", "and") %>% #replaces & with and
str_remove_all("^RT:? ") %>% #removes retweets
str_remove_all("@[[:alnum:]]*") %>% #removes mentions
str_remove_all("#[[:alnum:]]*") %>% #removes hashtags
str_remove_all("(?![.,])[[:punct:]]") %>% #removes punctuation except . and ,
str_replace_all("\\\n", " ") %>%
str_to_lower() %>% # Converts to lower case
str_trim("both") # Removes whitespace on both sides of string
}Programmatically cleaning Twitter data
Having a function that can clean the text variable of the Twitter data, I now need to load in the 42 .rds files, clean the text variable, and save 42 new .rds files keeping a backup of the raw data. To do this I will again use twitter_data.csv, first to read in the aforementioned data files, but also to save the cleaned data using the altpath column. Furthermore, Twitter data contains many variables (around 90) and as I’m only interested in looking at a few of these, and also have a backup of the raw data, I will select the variables of interest and retain these in the new data files. To do this I initialize a the R object voi containing the names of the variables to keep.
# Cleaning tweets programmatically
ref <- read.csv('twitter_data.csv', stringsAsFactors = FALSE) # .csv file containing path and altpath
voi <- c('user_id', 'status_id', 'created_at',
'text', 'hashtags', 'location',
'retweet_count', 'favorite_count', 'followers_count') # Variables of interestMuch like when collecting the Tweets I now loop through twitter_data.csv, loading each file using the path column and selecting the variables of interest or voi. Then the text variable of each file, is being passed to my function clean_tweets() before saving the data.frame as a new .rds file using the column altpath in twitter_data.csv.
# Looping through ref reading in datasets containing tweets and cleaning text variable
for (row in 1:nrow(ref)) {
df <- readRDS(ref$path[row]) %>%
select(all_of(voi))
df$text <- clean_tweets(df$text)
saveRDS(df, ref$altpath[row])
}Having an individual file for each query is nice for backup purposes, however, for analysis purposes, loading 42 individual files and applying the same operations on each doesn’t seem effective. Therefore, in this next section I will join the files together, to create two distinct data.frames during and after the first and final debate.
Joining multiple Twitter queries
In order to join the files together I need to load in the newly created clean .rds files. I do this by creating a list of data.frames and calling it df_list. I then use the function rbindlist, to bind the rows from the files pertaining to the first debate together, and remove duplicates using the function distinct on the variable status_id. The resulting data.frame is then saved as a new .rds file, and the same is done for the files pertaining to the final debate.
# Loading cleaned datasets as list of dataframes
df_list <- lapply(ref$altpath, readRDS)
ref_clean <- read.csv('twitter_data_clean.csv', stringsAsFactors = FALSE) # .csv file containing paths for cleaned data
# Combining cleaned datasets into two dataframes with regard to collection date
presdebate_first <- rbindlist(df_list[1:18]) %>%
distinct(status_id, .keep_all = TRUE) %>%
saveRDS(ref_clean$path[1])
presdebate_final <- rbindlist(df_list[19:39]) %>%
distinct(status_id, .keep_all = TRUE) %>%
saveRDS(ref_clean$path[2])This resulted in two RData .rds files containing a total of 325.314 unique tweets, which are now ready for analysis. If you are interested in checking out this project in more depth, the complete source code can be found on GitHub.